 Home
Home Services
Services Quadient Inspire
Quadient Inspire 



 Enterprise Services
Enterprise Services 






 Migration
Migration 




 Process Automation
Process Automation 



 Staffing Services
Staffing Services 





 Download Brochure
Download Brochure  Products
Products Resource Center
Resource Center Corporate Overview
Corporate Overview Careers
Careers Contact Us
Contact Us
Impact on Transcription and Scorecard Accuracy
Call Fidelity is without doubt the most important quality metric of the recorded calls being input to a speech analytics system such as Call Miner Eureka. It directly affects the ability of speech analytics software to generate accurate and readable transcripts and to convert the speech to accurate interaction data and scorecards.
This paper is the first of a two-part series, showing results of several simple case studies we performed internally on gauging impact of call fidelity on the accuracy of speech analytics results. The point of these case studies is to give quantitative flavor on how important call fidelity is to getting high accuracy of the speech analytics results.
This first paper provides a brief background and introduction to the subject, along with some results of our case studies for a few speech analytics measures. The second paper in the series will be available soon and will dig deeper into an assortment of speech analytics metrics and the relationship of their accuracy to call fidelity.
Background
It is surprising how often we encounter contact centers that really don’t know the quality of the recordings currently being captured and saved within their contact center. In more than a few of these cases, we find call fidelity to be way too low to give the best possible speech analytics results.
Given that higher fidelity generally means more storage requirements and thus more cost, in that sense this tendency for lower fidelity of stored conversations is not surprising as contact centers are generally seeking to optimize (lower) costs of operations. But as soon as Speech Analytics comes into the picture, then in our view the equation changes radically. Accurate speech analytics absolutely needs high fidelity recordings of the conversations. At a high level, it’s as simple as that.
Without the high fidelity it is very hard to draw out the full and complete meaning and value of the speech for use by the company both for real-time actions, as well as for the myriad of subsequent contact center, marketing and sales activities for which this speech analytics data can be valuable inputs.
Yes, as we discuss below, there are methods in modern speech analytics systems to draw out as much good content as possible even when fidelity is low, but the fact remains that without high fidelity it is not possible to draw out all the full content and meaning, and in our view the business case for moving to higher fidelity is extremely good!
As a technology partner of Call Miner, we work with clients to check call fidelity as early in the engagement process as possible. If we find fidelity is too low, we inform client, and work with their internal infrastructure team, as well as outside contact center software vendor (if any are involved) to rachet up the fidelity to good levels.
We work with the client team to explain and compare how fidelity level relates to accuracy of the final speech analytics outputs. While there is not an exact 1-to-1 relationship between call fidelity and speech analytics outputs, the overall positive relationship is clear and definite, and we work with our clients to show them this.
Call Fidelity and Speech Analytics
In audio analytics domain, audio quality is generally thought of as a combination of accuracy, fidelity and intelligibility of the audio output. As noted earlier, this audio is a direct input to the speech recognition/analytics engine, and so it goes without saying that audio fidelity plays a crucial role in transcription accuracy, and speech analytics outputs. But what exactly is the nature of that quantitative relationship, and how does it change for different metrics of interest in speech analytics.
For a call center business, a tool like CallMiner gives an amazing ability to automatically uncover actionable intelligence from your audio calls as input. But at its core, the system is as good as the audio calls being fed into it. From the perspective of Automatic Speech Recognition tool, the poorer the audio quality, the more difficult it is for the system to transcribe, which will lead to a less accurate transcript. Now, thinking it from the analysis perspective, a poorly transcribed call corpus in CallMiner will lead to:
- Low precision in categories and scores
- Require us to build a whole range of aliases for incorrectly transcribed keywords
- These aliases then mostly lead to more false positives in our categories and scores
- Much more time to implement scorecards
Aliases to the rescue
Aliases are generally considered a good way to compensate for poor transcription quality. With low call fidelity, the benefits of using aliases might outweigh their downside. But as we increase call fidelity and start getting more accurate transcriptions, these aliases will become less useful and you will start noticing all the false positives that you are now getting because of them. On top, don’t forget the extra time you had to spend on identifying these aliases in the first place. In all eventualities, it is always better to start off with good fidelity audio calls.
Quantifying the Impact of Fidelity
It’s a tricky business to try and quantify the impact of call fidelity improvement on your scorecard accuracy. There are lots of nuisances and confounding factors that may have an effect on your result(s). A more controlled experimental design is needed here.
In order to build more context around this design framework, let’s dive into a real-world scenario. For one of our clients at Macrosoft, during our on-boarding phase, we started getting much lower fidelity audio calls (24 kbps) as compared to what is recommended (i.e. 128 kbps). After a month, we were able to migrate our client to the recommended fidelity audio recording system.
But now then comes the million-dollar question; how much accuracy gain have we achieved with this transition to a higher fidelity system?
As mentioned earlier, there are lot of factors that can add biasness to our results, and we need to control them for an objective analysis. These factors include;
| Agent accent |
| Type of calls (skill group) |
| Silence on the call |
| Language of the call |
| Background noise |
To control for these dimensions, our analysis compared improvements at an agent level. Since agents are scheduled on pre-specified call skill groups, this methodology ensured that our framework is controlling for variations in accent and type of call. CallMiner also gives you the ability to quantity silence blocks in your calls. We used this feature to sample calls with similar silence blocks so as to avoid any biases because of this.
Language of the call
This is a difficult feature to control. A simple way around this problem is to measure accuracy improvement on a score level data. A score is generally defined around a similar set of language; for example, a score around agent greetings over the call will target a specific type of language. One idea here is to pick a score that is quite prevalent in your calls’ universe; this will ensure that we have a decent pool of calls at the agent level to get reliable estimates.
Background noise.
There is no straight forward method to capture this at call level. However, since agents are taking calls from a fixed location, it is a fair assumption that background noise will be equally distributed over all the selected calls for a given agent.
Summary Results
Based on our framework specified so far, we were able to observe and quantify an enormous 41% improvement in transcription accuracy at call level due to an increase in recording fidelity from 24kbps to 128 kbps.
At the same time, we observed a 3% increase in false positive rate because of our usage of aliases. As mentioned above, we use aliases to compensate for poor transcription quality. An overuse of aliasing with good transcription quality generally leads to an increase in the false positive rate in your transcription
In the 2nd paper in this series, we will dive much deeper into these results, showing the impact of this fidelity improvement on a range of different category scores. Moreover, we will show the impact on false positives as we remove the aliases from the category definitions for the higher fidelity recordings.
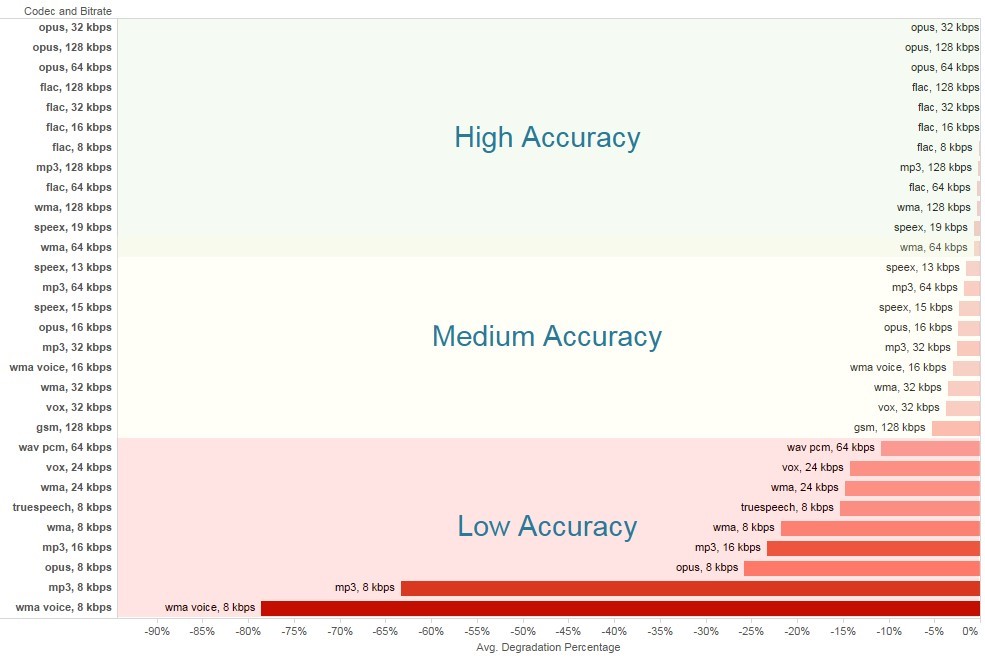
Call Fidelity Chart
The above observations show that audio file quality is the dominant factor of transcription quality. As a technology implementation partner of CallMiner, we cannot emphasize more on the importance of high recording quality.
Below is a table on the transcription accuracy for different audio formats and quality. We strongly recommend customers to use this chart as a reference to check whether your recording quality is ready for speech analytics. As shown in the chart – the low accuracy sector is very problematic for accurate speech analytics. In our opinion, this range should be avoided if at all possible. The results gained from speech analytics for call recordings in this fidelity range will be of modest value at best, and the transcriptions will not be acceptable at all.
In the medium-accuracy fidelity range, there is a fighting chance to gain good value from your speech analytics efforts, but frankly there will remain value not realized. Moreover, there will be very considerable effort required of the data scientist team to structure the speech analytics programs to get the best possible out of the recordings (e.g. introducing lots of aliases to the category definitions, which in turn will lead to increases in false positives).
At the high-accuracy fidelity range, the work of speech analytics flows easily, and the results are generally of high quality, and that includes the transcriptions as well as the many speech categories a client may set up to gauge interaction scores. While the work is still not a ‘cake-walk’ by any means it involves much less in the way of compensating structures, such as aliases. Moreover, and very importantly, it is much easier and straightforward to rally a client’s users to buy into automated speech analytics to assist and improve their daily work routines in many ways. The results of the speech analytics programs will be transparent – and users will be inclined to agree in most all cases with the automated results.
Conclusion & Contact Us
Based on our experiences on CallMiner engagements, clients usually store their recordings at lower fidelity to save space. While this is acceptable for manual reviews of transcriptions and for manual QA purposes, it is not sufficient for speech analysis purposes.
While it is possible to construct working speech analytics platforms using low fidelity recordings the results will generally not be satisfactory, and agents and managers will often not agree with the automated findings.
If your organization’s goal is to transition to auto QA with analysis of 100% of your customer interactions, or to use speech analysis for many other purposes, it is essential to give the speech analysis program high-accuracy fidelity recordings.
We recommend you check with your internal infrastructure organization or contact your call recording vendor to check your contact center’s current level of call fidelity. This really must be step one in engaging in an automated speech analysis work program. If the fidelity is not good enough, you need to consider upgrading the quality before beginning in earnest with your automated speech analytics work program.
As part of our customer on-boarding process, Macrosoft will work with you to examine your call fidelity to make sure it is sufficient for you to get the most out of CallMiner’s speech analytic platform. Not sure if your recording quality is ready for Speech Analysis, contact us and we will be happy to work with you to get the answer.
By Muhammad Saqib, Allen Shapiro, Ronald Mueller | November 17th, 2020 | CallMiner
About the Author

Muhammad Saqib
Saqib is a Data Science professional at Macrosoft with over 8 years of experience in the field. He enjoys breaking down complex business problems and solving them using data, statisticss and machine learning techniques. He has a penchant for natural language processing, reinforcement learning and time series analysis. He’s a long-time python enthusiast and a fan of data visualization, econometrics, nachos, and snooker. He holds a master’s degree in Data Science from University of California San Diego and a bachelor’s in economics from LUMS, Pakistan.

Allen Shapiro
Allen brings more than 25 years of diverse experience in Marketing and Vendor Management to Macrosoft Inc. As the Managing Director of our Customer Communications Management (CCM) practice, Allen leads the Onshore and Off-shore CCM development teams. Additionally, Allen oversees pre-sales activities and is responsible for managing the relationship with our CCM software provider Quadient.

Ronald Mueller
Ron is the Chairman and Founder of Macrosoft, Inc. He heads up all company strategic activities and directs day-to-day work of the Leadership Team at Macrosoft. As Macrosoft’s Chief Scientist, Ron defines and structures Macrosoft’s path forward. Ron's focus on new technologies and products, such as Cloud, Big Data, and AI/ML/WFP. Ron has a Ph.D. in Theoretical Physics from New York University and worked in physics for over a decade at Yale University, The Fusion Energy Institute in Princeton, New Jersey, and at Argonne National Laboratory.
Ron also worked at Bell Laboratories in Murray Hill, New Jersey., where he managed a group on Big Data. Ron's work focused around the early work on neural networks. Ron has a career-long passion in ultra-large-scale data processing and analysis including predictive analytics, data mining, machine learning and deep learning.
Recent Blogs

Advantages of Technology and IT Companies Partnering with Staffing Firms Offering Visa Sponsorship
Read Blog
CCM in the Cloud: The Advantages of Cloud-Based Customer Communication Management
Read Blog
The Rise of Intelligent Automation: A Roadmap for Success
Read Blog