 Home
Home Services
Services Quadient Inspire
Quadient Inspire 



 Enterprise Services
Enterprise Services 






 Migration
Migration 




 Process Automation
Process Automation 



 Staffing Services
Staffing Services 





 Download Brochure
Download Brochure  Products
Products Resource Center
Resource Center Corporate Overview
Corporate Overview Careers
Careers Contact Us
Contact Us
1. Executive Summary
Document Understanding (DU) is one of the fastest-growing areas in business process automation. The DU ecosystem includes technologies that can interpret and extract text and meaning from a wide range of document types including structured, semi-structured and unstructured — even ones that contain handwriting, tables and checkboxes. This is now possible because of the ever-improving techniques of Machine Learning (ML). Enhancements in ML are spurring innovation in document understanding.
In this article, we present the major steps in the DU process and the underlying architecture with reference specifically to UiPath’s Document Understanding framework.
Multiple technologies can unlock the power of document understanding such as:
- Optical Character Recognition (OCR)
- Many of the best-known OCR engines on the market are already integrated with UiPath. These include ABBYY, Tesseract (an open-source OCR provided by Google), Kofax OmniPage, Microsoft OCR, and Google OCR. In addition, UiPath Document OCR has recently been released as another great choice for customers.
- Template bases Extractors (TBEs)
- Supervised-learning-based machine learning extractors (SMLEs)
- Natural language processing (NLP)
In today’s business processes, most of the routine and mundane tasks employees perform consist of creating, reading, reviewing, and transcribing paperwork (documents). Employees spend a significant percentage of their work time reading these docs, extracting data, and passing on the much-needed information into other downstream applications manually. Since the data extraction from the documents and input to other apps is done by a human, the process is subject to problems of accuracy and reliability.
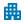
UiPath’s Document Understanding solution allows you to intelligently process data with a high level of accuracy and reliability for any type of document such as invoice, receipt, financial statement, utility bill, and any other kind of text that has a different structure. The general flow for UiPath’s DU process is encapsulated into the 6 process steps below.
To decide which steps are needed for a specific business process, you will need to address the below requirements:
- Do we need only to classify the documents?
- Do we need to classify and extract data from documents?
- Who will be handling the manual verification when needed?
- How would you escalate verification needs to higher management?
- What is the basis of verification and escalation to management?
One primary concern of the solution is that it should not stop the entire process until a human performs a manual verification. The process should escalate the check to the respective party, while at the same time continuing to evaluate and process the rest of the documents.
2. Classification Based Approach
There are scenarios where data extraction is not essential, and the priority is only to segregate the documents based only on classification, for further processing later in another process. In such cases, the UiPath DU solution comes in very handy as it provides the capability to classify documents based on keywords.
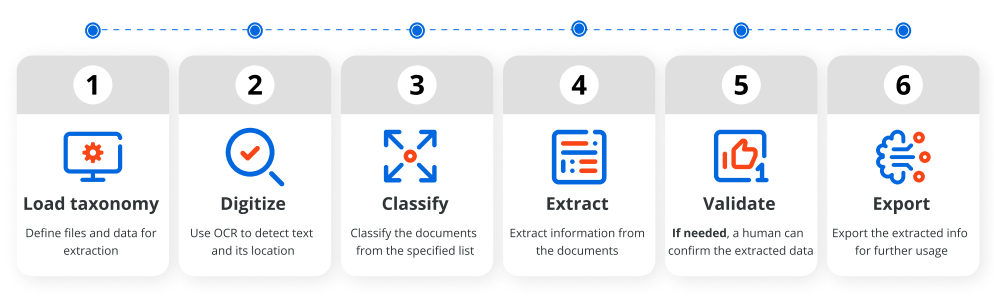
The solution offers the ability to train the classifiers intelligently when setting up the automation solution. These classifiers will also continue to learn every time a document is classified (and verified by a human) thus improving accuracy over time. The classification and verification process steps are suitable for attended automation. The attended automation provides a Classification Station, where a user can verify and correct the classification if the confidence is below a predefined value. A schematic of the process is shown in the below chart.
Classification Process
In most business scenarios, classification is not the only requirement. Most processes will also require the extraction of data from the documents and processing of the extracted data according to specified business requirements. However, even in this case, we cannot ignore the classification process step in the automated approach, as it is essential to identify the type of document so that the robot knows how and what fields to extract.
Different methods are available to handle manual verification of classification results:
- Attended only approach
- Validation Station will be used to show the validation screen on the machine the process is executing. This approach is also ideal when UiPath Orchestrator is not being used.
- Unattended only approach
- Uses Action Centre to handle human involvement.
- Hybrid approach
Use attended and unattended collaboration in scenarios where the process should be manually triggered. If the same user who triggered the process is doing the validation, the use of a Validation Station is possible. However, based on the business logic, if certain exceptional cases need management approval, such escalations can be directed to the Action Centre directly without showing to the user at the Validation Station.
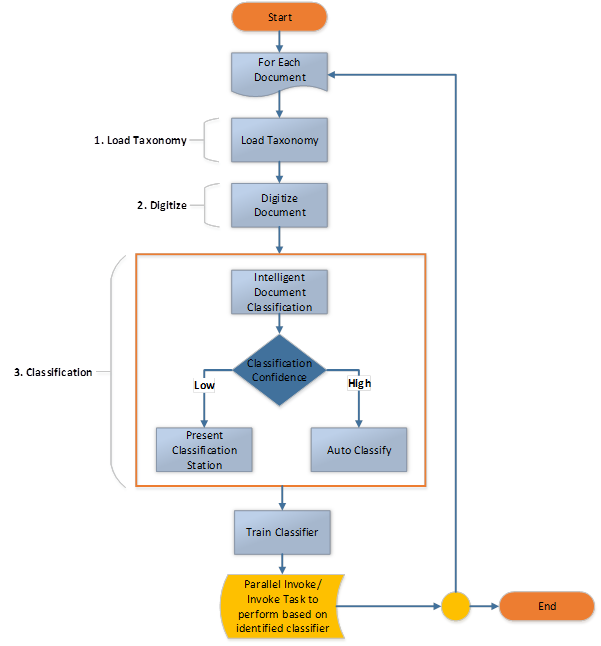
When designing a Document Understanding solution, it is a good practice to break the solution into separate manageable sub-processes. As a generic solution that fits for most cases, we could introduce three sub-processes to handle the Document Understanding Framework.
This high-level diagram showcases a sample architecture for the Document Understanding process. The architecture used here breaks the entire document understanding process into three main sub-processes. The three main components are Initiator process along with processing logic (Process 1), UiPath Action Centre for task assignment and management (Process 2), and finally, the Train models component (Process 3) which handles the training of the intelligent classifiers and also the passing of the extracted data to other applications.
The detailed architecture of each part is as follows.
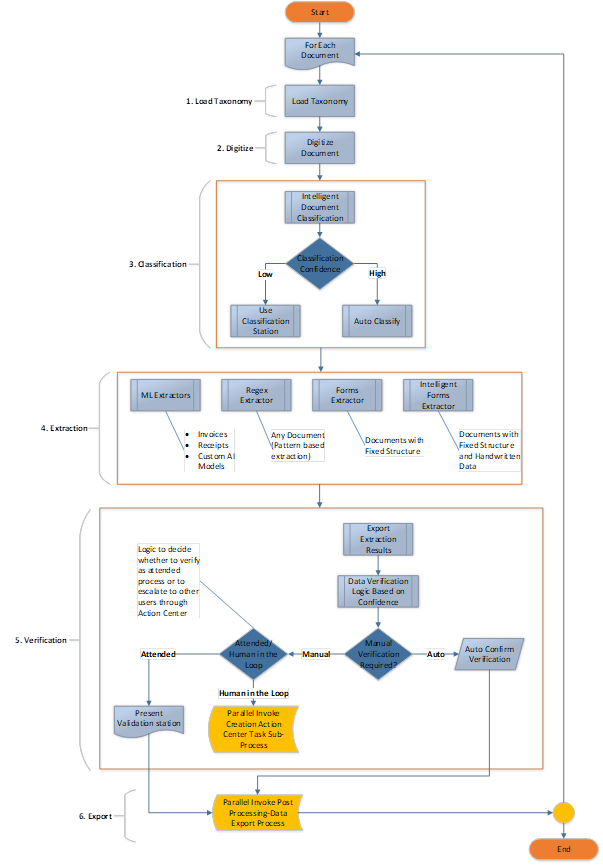
Process-1: The initiator Process
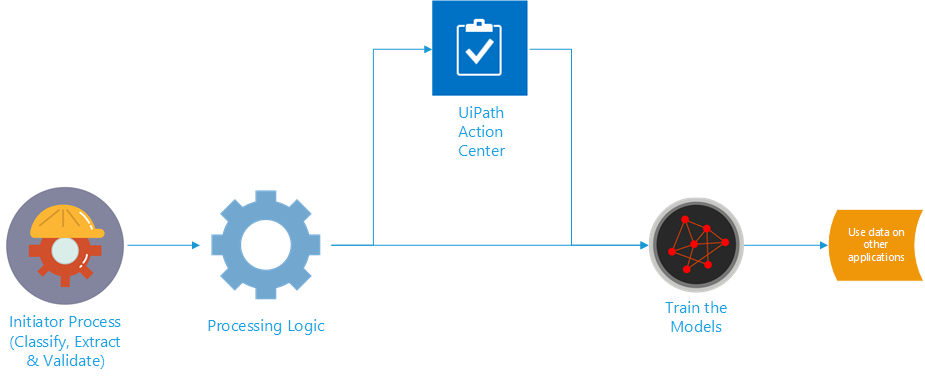
The Initiator process is the primary process that handles document classification, data extraction, and verification logic. The verification logic will include the rules that define how to handle verifications automatically, either through the use of the Validation Station, Action Centre, or both when human intervention is needed.
Depending on the option chosen in the validation logic, the extracted data will finally be passed to either the Action Centre Processor or to Post Processing to continue to the next steps. The diagram below shows a sample architecture for the Initiator Process.
Process 1: Initiator Process
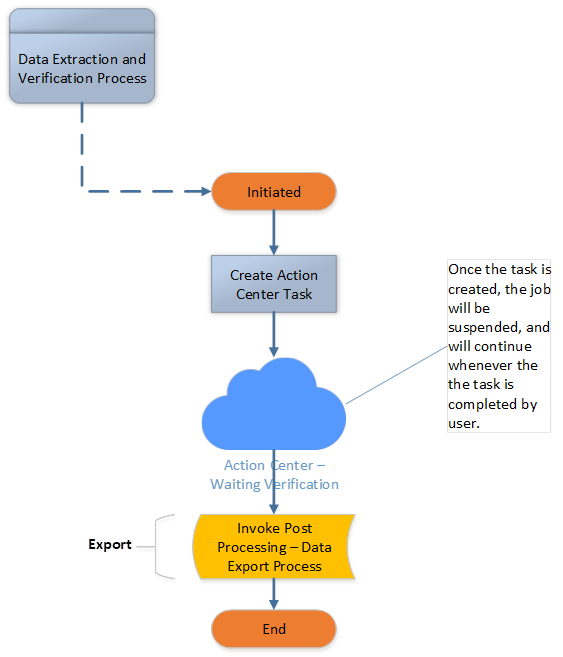
Process 2: Action Center
The Action Centre is the process that handles task creation, waits for task completion, and finally passes the data to the Post Processing portion for the end of Document Understanding. The diagram below shows a sample architecture for the Action Center process.
Process 2: Action Center Process Architecture
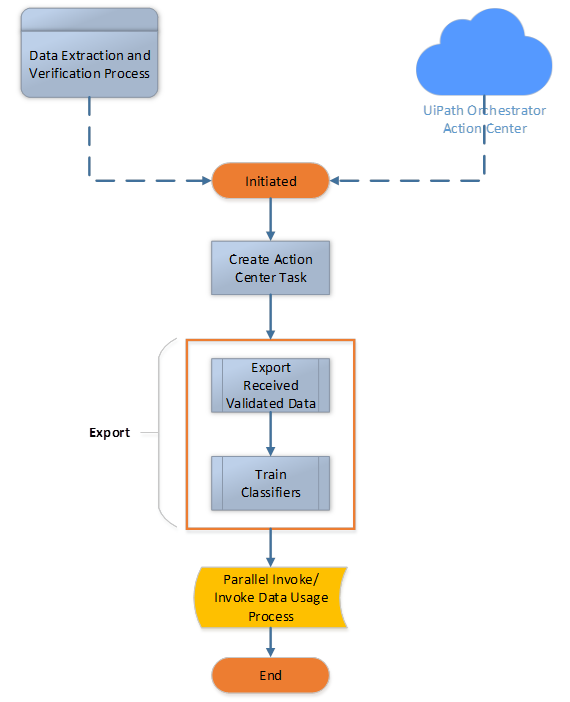
Process 3: Post Processing
The post-processing includes the steps needed for exporting the final verified data, training the models, and finally, passing the data to a different process outside the document understanding framework to continue with any system interactions, etc.
The data is handed over to a separate process because such steps are not part of document understanding and those should be maintained independently to maintain integrity and reusability of each component/ process. The diagram below shows a sample architecture design for the final stage of the document understanding framework, and it also showcases how Process 2 connects with Process 3.
Process 3: Post Processing Solution Architecture
Conclusion
Although the specifics of the business process may change from one company to another, the core architecture and process steps showcased above remain largely the same across most DU process implementations.
This blog is a quick overview of the major steps involved in the Document Understanding process. DU is one of the most powerful methods available today for automating your business processes, and we recommend you take a close look to see if it can be applied within your company. We will be happy to work with you to see if DU has a role to play in your company.
By Imaan Ali, Ronald Mueller | December 3rd, 2020 | Process Automation
About the Author

Imaan Ali
Imaan Ali has been working as a Data Engineer at Macrosoft for 5 months, previously having been a Macrosoft summer intern working in chatbot technology. Imaan has a particular area of focus of Process Mining software and Robotic Process Automation.
Imaan provides service to clients through research in the best PM tools and finding the ones that are most cost-effective for customers.
Imaan is currently a sophomore at New Jersey Institute of Technology, pursuing a Bachelor's degree in Computer Science. She is fluent in Python and has a passion for discovering all the things CS is capable of achieving.

Ronald Mueller
Ron is the Chairman and Founder of Macrosoft, Inc. He heads up all company strategic activities and directs day-to-day work of the Leadership Team at Macrosoft. As Macrosoft’s Chief Scientist, Ron defines and structures Macrosoft’s path forward. Ron's focus on new technologies and products, such as Cloud, Big Data, and AI/ML/WFP. Ron has a Ph.D. in Theoretical Physics from New York University and worked in physics for over a decade at Yale University, The Fusion Energy Institute in Princeton, New Jersey, and at Argonne National Laboratory.
Ron also worked at Bell Laboratories in Murray Hill, New Jersey., where he managed a group on Big Data. Ron's work focused around the early work on neural networks. Ron has a career-long passion in ultra-large-scale data processing and analysis including predictive analytics, data mining, machine learning and deep learning.
Recent Blogs

Humanizing Automation: Fostering Collaboration in the Digital Era
Read Blog
Advantages of Technology and IT Companies Partnering with Staffing Firms Offering Visa Sponsorship
Read Blog
CCM in the Cloud: The Advantages of Cloud-Based Customer Communication Management
Read Blog